O Twitter é racista? Entenda como funciona os algoritmos de reconhecimento facial
Uma discussão tomou a rede social neste final de semana questionando o fato do algoritmo privilegiar as pessoas brancas em suas imagens. O problema pode indicar viéses em sua inteligência artificial e tecnologia de reconhecimento facial. Confira:


Neste final de semana, uma discussão sobre o Twitter ser racista e carregar um algoritmo problemático tomou da rede. Testes realizados por usuários inesperadamente mostraram que o algoritmo da rede social privilegia mostrar imagens de pessoas brancas com mais frequência do que negras em sua ferramenta de corte automático.
Um usuário publicou duas versões da mesma imagem, que constam fotos do senador norte-americano Mitch McConnell e o ex-presidente Barack Obama. As imagens na vertical contam com uma imagem de cada em cada ponta. Em ambas, a imagem de destaque selecionada foi a do McConnell, homem branco.
https://twitter.com/bascule/status/1307440596668182528
Logo muitos usuários utilizaram suas contas para testar diferentes combinações de imagens (o que incluiu até testes envolvendo as cores dos pelos de animais de estimação), procurando respostas no fundo das imagens, no brilho, contraste e o caso também alcançou as contas brasileiras.
Teste – Os algoritmos do Twitter priorizam pessoas brancas pic.twitter.com/YBbQ1ItfRR
— Luiz Guilherme Prado (@luizguiprado) September 20, 2020
Após os testes, com ar de denúncia, repercutirem na rede, algumas pessoas se manifestaram. Parag Agrawal, diretor de tecnologia do Twitter, disse que “essa é uma perguna muito importante. Para resolver isso, fizemos análises em nosso modelo quando o enviamos, mas precisa de melhoria contínua. Adoro este teste público, aberto e rigoroso – e ansioso por aprender com ele”.
This is a very important question. To address it, we did analysis on our model when we shipped it, but needs continuous improvement.
Love this public, open, and rigorous test — and eager to learn from this. https://t.co/E8Y71qSLXa
— Parag Agrawal (@paraga) September 20, 2020
Já o chefe de Design e Pesquisa da empresa, Dantley Davis, assumiu a responsabilidade em seu perfil pessoal. “É 100% nossa culpa. Ninguém deveria dizer o contrário. O próximo passo agora é resolver”.
It’s 100% our fault. No one should say otherwise. Now the next step is fixing it.
— Dantley Davis (@dantley) September 19, 2020
Como a ferramenta funciona?
Lançada em 2018, a ferramenta de corte inteligente existe para melhorar a experiência do usuário. Para decidir como o corte será feito, eles utilizam o reconhecimento facial para destacar as partes mais ‘salientes’ das imagens. Entretanto, a abordagem possui suas limitações. “Nosso detector de rostos muitas vezes erra os rostos e às vezes detecta rostos onde não existe. Se não encontrarmos nenhum rosto, nós focaremos a visualização no centro da imagem”, é o que afirma o conteúdo assinado por Lucas Theis e Zehan Wang sobre a ferramenta publicado no blog oficial da empresa em 2018.

Portanto, as regiões salientes são aquelas em que são mais prováveis que a pessoa olhe quando visualiza a imagem livremente. “Em geral, pessoas prestam mais atenção em rostos, textos, animais, mas também outros objetos e regiões de alto contraste”. Esses dados são usadoa para treinar redes neurais e outros algoritmos para predizer “o que as pessoas podem querer olhar”.
Através do sistema de redes neurais artificiais, se inspirando no sistema nervoso central, a máquina é capaz de aprender e reconhecer padrões. Porém, sabe-se que a inteligência artificial já registrou inúmeros problemas.
Problemáticas dos dados
O Twitter é racista? A resposta pode ser não, mas se engana quem acredita que os dados representam uma verdade absoluta. Principalmente quando falamos de dados e inteligência artificial, que podem espelhar preconceitos dos próprios desenvolvedores.
O Machine Learning, ou Aprendizado de Máquina, é uma das áreas mais populares da IA. Em resumo, o computador aprende com a experiência a partir dos padrões de dados históricos. Todavia, eles podem ser racistas, misóginos ou descriminatórios. Assim, segue-se uma lógica de algoritmo que segue vieses ou com uma distorção sistemática.
É disso que comentam Marcelo Costa, analista de dados, e Rodrigo Kramper, líder da prática de Advanced Data and Analytics Solutions na ICTS Protiviti, em seu artigo “Black Lives Matter: os algoritmos da minha empresa reforçam a discriminação?”, na Revista da Call Center.
“Normalmente, esses problemas decorrem da construção de modelos sem conhecimento e sem a correção de vieses ocultos, o que pode levar a resultados distorcidos, tendenciosos ou mesmo errados, reforçando estigmas sociais, econômicos e raciais, além de institucionalizá-los com o requinte de parecerem resultados científicos, já que são baseados em modelos matemáticos”, afirmam em seu artigo.
Além dos dados históricos, a aprendizagem de máquina também pode contar com: viés de amostragem, onde a amostra analisada pelo algoritmo é incompleta ou não apresenta o ambiente executado; viés de preconceito, modelos treinados por dados influenciados por esteriótipos ou fatores culturais; e o viés do observador, que traz preconceitos do próprio profissional de dados.
O Twitter se manifestou oficialmente em sua conta, bem como afirmou que diversos testes foram feitos antes de lançarem o modelo e não encontraram evidências de preconceito racial ou de gênero, porém existem mais análises para serem feitas.
Fizemos uma série de testes antes de lançar o modelo e não encontramos evidências de preconceito racial ou de gênero. Está claro que temos mais análises a fazer. Continuaremos compartilhando nossos aprendizados e medidas, e abriremos o código para que outros possam revisá-lo. https://t.co/yZphB9pK5p
— Twitter Brasil em ? (@TwitterBrasil) September 21, 2020
Reconhecimento facial e viés
Antes de tudo, a tecnologia de reconhecimento facial possui um potencial para a exclusão e representação, já que possui um alto índice de erro. O Twitter não é o primeiro nas polêmicas racistas. Um breve exemplo: em 2015, Jacky Alcine twittou que o aplicativo de fotos do Google nomeou automaticamente imagens dele e de sua namorada negra com a palavra “gorilas”.
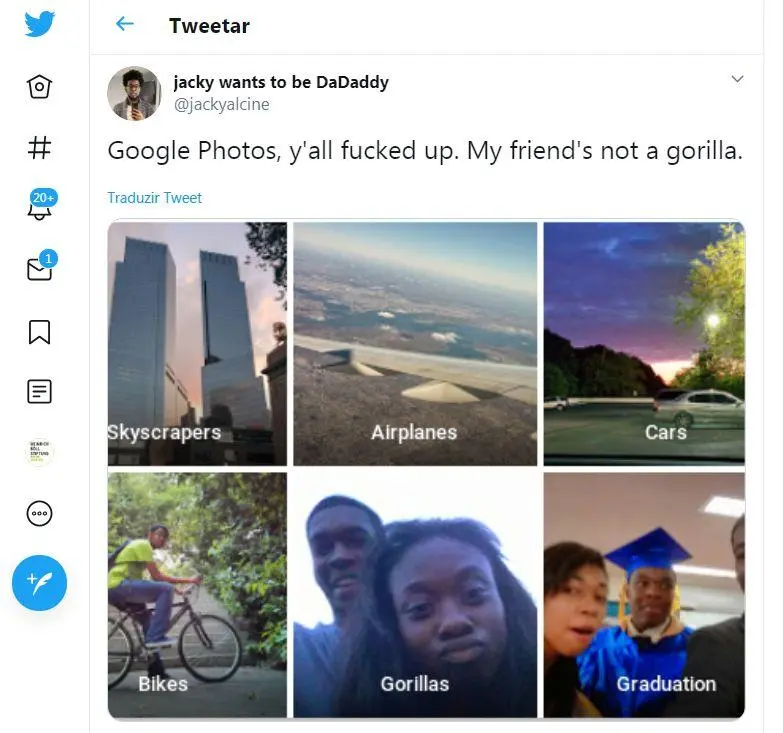
Dessa forma, o Google se desculpou pelo ocorrido, colocando a culpa em seu sistema de reconhecimento facial. Contudo, algum tempo depois, em uma matéria feita pelo Wired, aparentemente a solução dada pela empresa foi removendo os gorilas das pesquisas ou tags.
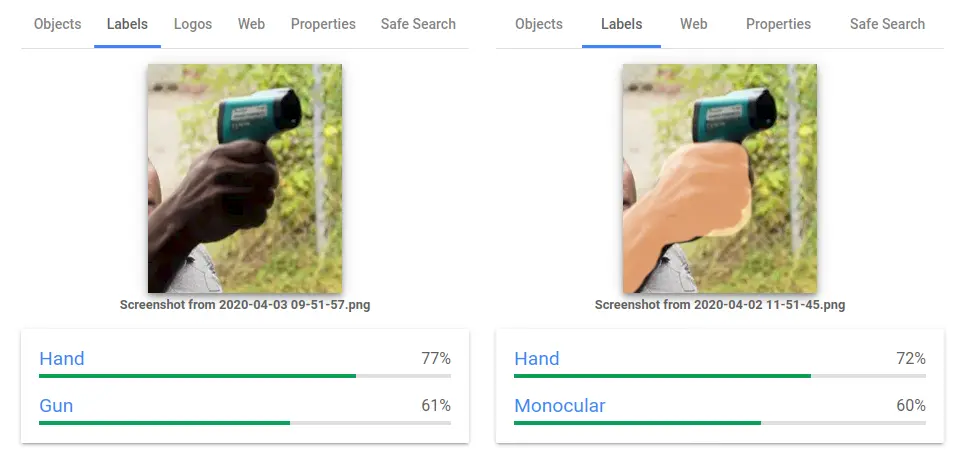
Se você deseja considerar os cinco anos que nos separam do caso, em abril deste ano o Google pediu publicamente desculpas por seu sistema apresentar dois resultados diferentes na categorização para fotos com pele negra e branca.
Na imagem onde uma mão negra segura um termômetro de mão, o sistema marcou “mão” e “arma”. Por outro lado, quando é apresentada a mesma imagem com uma mão branca, ela foi marcada como “mão” e “monocular”.
Plataforma Zoom
Outro caso, que também acompanhou discussões no último final de semana no Twitter, foi de um estudante que compartilhou imagens da sua reunião utilizando a plataforma Zoom. Enquanto a reunião acontecia com seu professor negro, as imagens o mostram desaparecendo quando ele insere um fundo virtual, que depende do reconhecimento de rostos. Porém, o problema não ocorreu com seu aluno branco.
A faculty member has been asking how to stop Zoom from removing his head when he uses a virtual background. We suggested the usual plain background, good lighting etc, but it didn't work. I was in a meeting with him today when I realized why it was happening.
— Colin, but at home. (@colinmadland) September 19, 2020
“O ponto é que a precisão e o preconceito de tecnologias, como o reconhecimento facial são apenas uma forma pela qual as comunidades marginalizadas experimentam uma discriminação nova e automatizada”, menciona Fabian Taute em seu artigo Reconhecimento Facial e suas controvérsias. “O software aprende a partir da coleta de uma base de dados muito grande e assim consegue detectar a diferença entre uma face humana e a de um porco, por exemplo. A medida em que o treinamento é feito por pessoas da área da tecnologia que são na grande maioria homens brancos e de classes médias, há uma enorme falta de diversidade nessa área o que é transmitido no código do reconhecimento facial”.
Existem saídas?
De acordo com Costa e Kramper em seu artigo, “um começo promissor reside em conhecer os dados, a sua qualidade e proporcionalidade amostral, assim como ter pensamento crítico sobre fatores históricos e sociais que podem influenciar os dados, assim como o uso de diversidade nos times de desenvolvimento. Trazer visões e experiências diferentes aos projetos é um bom começo para o uso correto dos algoritmos de aprendizado de máquina”.
Dessa maneira, codificar também é questionar. Apesar de não podermos afirmas objetivamente que o Twitter é racista, não se pode crer que os dados e a inteligência artificial são livres de viés e preconceito, já que existem pessoas por trás das codificações. Assim, a resposta para as questões está na diversidade e representatividade dentro dos espaços.